La computación paralela es una forma de cómputo en la que muchas instrucciones se ejecutan Simultáneamente, operando sobre el principio de que problemas grandes, a menudo se pueden dividir en unos más pequeños, que luego son resueltos simultáneamente (en paralelo). Hay varias formas diferentes de computación paralela: paralelismo a nivel de bit, paralelismo a nivel de instrucción, paralelismo de datos y paralelismo de tareas. El paralelismo se ha empleado durante muchos años, sobre todo en la computación de altas prestaciones, pero el interés en ella ha crecido últimamente debido a las limitaciones físicas que impiden el aumento de la frecuencia.
Las computadoras paralelas pueden clasificarse según el nivel de paralelismo que admite su hardware: equipos con procesadores multinúcleo y multi-procesador que tienen múltiples elementos de procesamiento dentro de una sola máquina y los clústeres, MPPS y grids que utilizan varios equipos para trabajar en la misma tarea. Muchas veces, para acelerar las tareas específicas, se utilizan arquitecturas especializadas de computación en paralelo junto a procesadores tradicionales. Los programas informáticos paralelos son más difíciles de escribir que los secuenciales, porque la concurrencia introduce nuevos tipos de errores de software, siendo las condiciones de carrera los más comunes. La comunicación y sincronización entre diferentes subtareas son algunos de los mayores obstáculos para obtener un buen rendimiento del programa paralelo. La máxima aceleración posible de un programa como resultado de la paralelización se conoce como la ley de Amdahl.
Tipos de computación paralela
PARALELISMO A NIVEL DE BIT Desde el advenimiento de la integración a gran escala (VLSI) como tecnología de fabricación de chips de computadora en la década de 1970 hasta alrededor de 1986, la aceleración en la arquitectura de computadores se lograba en gran medida duplicando el tamaño de la palabra en la computadora, la cantidad de información que el procesador puede manejar por ciclo. El aumento del tamaño de la palabra reduce el número de instrucciones que el procesador debe ejecutar para realizar una operación en variables cuyos tamaños son mayores que la longitud de la palabra. Por ejemplo, cuando un procesador de 8 bits debe sumar dos enteros de 16 bits, el procesador primero debe adicionar los 8 bits de orden inferior de cada número entero con la instrucción de adición, a continuación, añadir los 8 bits de orden superior utilizando la instrucción de adición con acarreo que tiene en cuenta el bit de acarreo de la adición de orden inferior, en este caso un procesador de 8 bits requiere dos instrucciones para completar una sola operación, en donde un procesador de 16 bits necesita una sola instrucción para poder completarla.
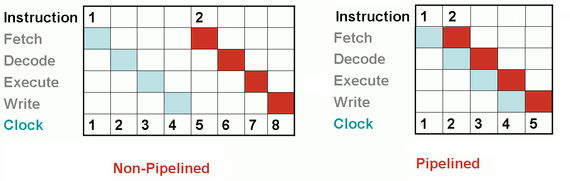
PARALELISMO A NIVEL DE INSTRUCCIÓN Un programa de ordenador es, en esencia, una secuencia de instrucciones ejecutadas por un procesador. Estas instrucciones pueden reordenarse y combinarse en grupos que luego son ejecutadas en paralelo sin cambiar el resultado del programa. Esto se conoce como paralelismo a nivel de instrucción. Los avances en el paralelismo a nivel de instrucción dominaron la arquitectura de computadores desde mediados de 1980 hasta mediados de la década de 1990.
Los procesadores modernos tienen »pipeline» de instrucciones de varias etapas. Cada etapa en el pipeline corresponde a una acción diferente que el procesador realiza en la instrucción correspondiente a la etapa; un procesador con un pipeline de N etapas puede tener hasta n instrucciones diferentes en diferentes etapas de finalización. El ejemplo canónico de un procesador segmentado es un procesador RISC, con cinco etapas: pedir instrucción, decodificar, ejecutar, acceso a la memoria y escritura. El procesador Pentium 4tenía un pipeline de 35 etapas.
Además del paralelismo a nivel de instrucción del pipelining, algunos procesadores pueden ejecutar más de una instrucción a la vez. Estos son conocidos como procesadores superes calares. Las instrucciones pueden agruparse juntas sólo si no hay dependencia de datos entre ellas. El scoreboarding y el algoritmo de Tomasulo (que es similar a scoreboarding pero hace uso del ) son dos de las técnicas más comunes para implementar la ejecución fuera de orden y la paralelización a nivel de instrucción.
PARALELISMO DE DATOS El paralelismo de datos es el paralelismo inherente en programas con ciclos, que se centra en la distribución de los datos entre los diferentes nodos computacionales que deben tratarse en paralelo. La paralelización de ciclos conduce a menudo a secuencias similares de operaciones (no necesariamente idénticas) o funciones que se realizan en los elementos de una gran estructura de datos. Muchas de las aplicaciones científicas y de ingeniería muestran paralelismo de datos.
Una dependencia de terminación de ciclo es la dependencia de una iteración de un ciclo en la salida de una o más iteraciones anteriores. Las dependencias de terminación de ciclo evitan la paralelización de ciclos.
Este bucle no se puede paralelizar porque CUR depende de sí mismo (PREV2) y de PREV1, que se calculan en cada iteración del bucle. Dado que cada iteración depende del resultado de la anterior, no se pueden realizar en paralelo. A medida que el tamaño de un problema se hace más grande, la paralelización de datos disponible generalmente también lo hace.
PARALELISMO DE TAREAS El paralelismo de tareas es la característica de un programa paralelo en la que cálculos completamente diferentes se pueden realizar en cualquier conjunto igual o diferente de datos. Esto contrasta con el paralelismo de datos, donde se realiza el mismo cálculo en distintos o mismos grupos de datos. El paralelismo de tareas por lo general no escala con el tamaño de un problema.
Durante muchos años, la computación paralela se ha aplicado en la computación de altas prestaciones, pero el interés en ella ha aumentado en los últimos años debido a las restricciones físicas que impiden el escalado en frecuencia.
La computación paralela se ha convertido en el paradigma dominante en la arquitectura de computadores, principalmente en los procesadores multinúcleo.
Sin embargo, recientemente, el consumo de energía de los ordenadores paralelos se ha convertido en una preocupación.
Los ordenadores paralelos se pueden clasificar según el nivel de paralelismo que admite su hardware: los ordenadores multinúcleo y multiproceso tienen varios elementos de procesamiento en una sola máquina, mientras que los clusters, los MPP y los grids emplean varios ordenadores para trabajar en la misma tarea.
Los programas de ordenador paralelos son más difíciles de escribir que los secuenciales porque la concurrencia introduce nuevos tipos de errores de software, siendo las condiciones de carrera los más comunes.
La comunicación y la sincronización entre las diferentes subtareas son típicamente las grandes barreras para conseguir un buen rendimiento de los programas paralelos.
El incremento de velocidad que consigue un programa como resultado de la paralelización viene dado por la ley de Amdahl.
Clasificación
Las computadoras paralelas se pueden clasificar de acuerdo con el
nivel en el que el hardware soporta paralelismo. Esta clasificación es
análoga a la distancia entre los nodos básicos de cómputo. Estos no
son excluyentes entre sí, por ejemplo, los grupos de
multiprocesadores simétricos son relativamente comunes.
Computación multinúcleo: un procesador multinúcleo es un procesador que incluye múltiples unidades de ejecución (núcleos) en el mismo chip. Un procesador multinúcleo puede ejecutar múltiples instrucciones por ciclo de secuencias de instrucciones múltiples.
Multiprocesamiento simétrico: un multiprocesador simétrico (SMP) es un sistema computacional con múltiples procesadores idénticos que comparten memoria y se conectan a través de un bus. La contención del bus previene el escalado de esta arquitectura.
Computación en clúster: un clúster es un grupo de ordenadores débilmente acoplados que trabajan en estrecha colaboración, de modo que en algunos aspectos pueden considerarse como un solo equipo.
Procesamiento paralelo masivo: tienden a ser más grandes que los clústeres, con «mucho más» de 100 procesadores. En un MPP, cada CPU tiene su propia memoria y una copia del sistema operativo y la aplicación.
Computación distribuida: la computación distribuida es la forma más distribuida de la computación paralela. Se hace uso de ordenadores que se comunican a través de la Internet para trabajar en un problema dado.
Computadoras paralelas especializadas: dentro de la computación paralela, existen dispositivos paralelos especializados que generan interés. Aunque no son específicos para un dominio, tienden a ser aplicables sólo a unas pocas clases de problemas paralelos.
Cómputo reconfigurable con arreglos de compuertas programables: el cómputo reconfigurable es el uso de un arreglo de compuertas programables (FPGA) como coprocesador de un ordenador de propósito general.
Cómputo de propósito general en unidades de procesamiento gráfico (GPGPU): es una tendencia relativamente reciente en la investigación de ingeniería informática. Los GPUs son co-procesadores que han sido fuertemente optimizados para procesamiento de gráficos por computadora.
Circuitos integrados de aplicación específica: debido a que un ASIC (por definición) es específico para una aplicación dada, puede ser completamente optimizado para esa aplicación. Como resultado, para una aplicación dada, un ASIC tiende a superar a un ordenador de propósito general.
Procesadores vectoriales: pueden ejecutar la misma instrucción en grandes conjuntos de datos. Tienen operaciones de alto nivel que trabajan sobre arreglos lineales de números o vectores.
Arquitectura de computadores secuenciales
A diferencia de los sistemas combinacionales, en los sistemas secuenciales, los valores de las salidas, en un momento dado, no dependen exclusivamente de los valores de las entradas en dicho momento, sino también de los valores anteriores. El sistema secuencial más simple es el biestable.
La mayoría de los sistemas secuenciales están gobernados por señales de reloj. A éstos se los denomina "síncronos" o "sincrónicos", a diferencia de los "asíncronos" o "asincrónicos" que son aquellos que no son controlados por señales de reloj.
A continuación se indican los principales sistemas secuenciales que pueden encontrarse en forma de circuito integrado o como estructuras en sistemas programados:
Contador
Registros
En todo sistema secuencial nos encontraremos con:
Un conjunto finito, n, de variables de entrada (X1, X2,..., Xn).
Un conjunto finito, m, de estados internos, de aquí que los estados secuenciales también sean denominados autómatas finitos. Estos estados proporcionarán m variables internas (Y1,Y2,..., Ym).
Un conjunto finito, p, de funciones de salida (Z1, Z2,..., Zp).
Dependiendo de cómo se obtengan las funciones de salida, Z, los sistemas secuenciales pueden tener dos estructuras como las que se observan en la siguiente figura, denominadas autómata de Moore, a), y autómata de Mealy, b).
Tipos de sistemas secuenciales
En este tipo de circuitos entra un factor que no se había considerado
en los circuitos combinacionales, dicho factor es el tiempo, según
como manejan el tiempo se pueden clasificar en: circuitos
secuenciales síncronos y circuitos secuenciales asíncronos.
Circuitos secuenciales asíncronos.
En circuitos secuenciales asíncronos los cambios de estados ocurren
al ritmo natural asociado a las compuertas lógicas utilizadas en su
implementación, lo que produce retardos en cascadas entre los
biestables del circuito, es decir no utilizan elementos especiales de
memoria, lo que puede ocasionar algunos problemas de
funcionamiento, ya que estos retardos naturales no están bajo el
control del diseñador y además no son idénticos en cada compuerta
lógica.
Circuitos secuenciales síncronos.
Los circuitos secuenciales síncronos solo permiten un cambio de
estado en los instantes marcados o autorizados por una señal de
sincronismo de tipo oscilatorio denominada reloj (cristal o circuito
capaz de producir una serie de pulsos regulares en el tiempo), lo que
soluciona los problemas que tienen los circuitos asíncronos
originados por cambios de estado no uniformes dentro del sistema o
circuito.
Organización de direcciones de memoria
La memoria de acceso secuencial son memorias en la cuales para acceder a un registro en particular se tienen que leer registro por registro desde el inicio hasta alcanzar el registro particular que contiene el dato que se requiere.
Organización lógica
Los programas a menudo están organizados en módulos, algunos de los cuales
pueden ser compartidos por diferentes programas, algunos son de sólo-lectura y
otros contienen datos que se pueden modificar. La gestión de memoria es
responsable de manejar esta organización lógica, que se contrapone al espacio de
direcciones físicas lineales. Una forma de lograrlo es mediante la segmentación de
memoria.
Organización física
La memoria suele dividirse en un almacenamiento primario de alta velocidad y uno
secundario de menor velocidad. La gestión de memoria del sistema operativo se
ocupa de trasladar la información entre estos dos niveles de memoria
Sistemas de memoria (compartida) Multiprocesadores
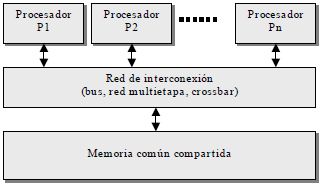
Cada procesador posee su propia unidad de control ejecuta su propio código sobre sus propios datos, puede ejecutar cualquier aplicación (no solo programas vectoriales).
Todos los procesadores acceden a una memoria común.
La comunicación entre procesadores se hace a través de la memoria.
Se necesitan primitivas de sincronismo para asegurar el intercambio de datos.
Memoria Compartida Centralizada: La memoria compartida por todos los procesadores y accesible desde cualquiera. Descompuesta en varios módulos para permitir el acceso concurrente de varios procesadores Cada procesador debe tener un espacio de direccionamiento suficientemente amplio como para poder direccionarla completamente. Multiprocesador con un sistema de memoria compartida en el cual el tiempo de acceso varía dependiendo de la ubicación de la palabra de memoria. La memoria compartida se distribuye físicamente por todos los procesadores (memorias locales). El conjunto de memorias locales forma el espacio de direccionamiento global accesible por todos los procesadores. En los multiprocesadores cada procesador suele tener asociada una cache local y ello introduce el problema de la coherencia en chache: cualquier modificación local de una determinada posición de la memoria compartida se realizará primeramente sobre un chache local y ello puede dar lugar a una visión global incoherente de la memoria. Los elementos que integran un multiprocesador pueden estar conectados entre sí a través de una estructura Jerárquica de buses.
Redes de interconexión dinámica (indirecta).
Medio compartido.
Conmutadas.
Características:
Antes de definir las características de las redes de interconexión diremos que se llama nodo a cualquiera de los dispositivos que se quiera conectar a la red, tales como elementos de proceso, módulos de memoria, procesadores de entrada/salida, etc.
Grado de los nodos
Diámetro de una red
Ancho de bisección
Latencia de una red
Productividad
Productividad
Simetría
Conectividad
Clasificación de Redes de interconexión:
El criterio más importante para la clasificación de las redes de interconexión se basa en la rigidez de los enlaces entre los nodos: a este respecto a las redes pueden clasificarse en estáticas o dinámicas. Una red estática se caracteriza porque su topología queda establecida de forma definitiva y estable cuando se instala un sistema; su única posibilidad de modificación es crecer. Por el contrario, una red dinámica puede variar de topología bien durante el curso de la ejecución o de los procesos o bien entre la ejecución de los mismos. Por otra parte, las redes pueden ser jerárquicas o no, los son si están formadas por una serie de niveles, con diferente número de nodos, dentro de cada uno de los cuales existe simetría. La mayoría de las redes jerárquicas suelen ser estáticas, sin embargo, hay algún tipo de topología dinámica que también puede serlo.
Redes de interconexión dinámicas:
Las redes de interconexión dinámicas son convenientes en los casos en que se desee una red de propósito general ya que son fácilmente reconfigurables. También por eso, este tipo de Redes facilitan mucho la escalabilidad. En general, las redes dinámicas necesitan de elementos de conexión específicos como pueden ser árbitros de bus, conmutadores, etc. Las principales topologías de redes dinámicas son las siguientes:
Buses
Redes de líneas cruzadas o matriz de conmutación (crossbar)
Redes multietapa o MIN (Multistage Interconnection Network)
Redes Omega
Redes de línea base
Redes Mariposa
Redes Delta
Redes de Closs
Redes de Benes
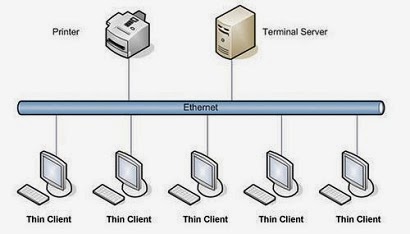
Entorno de medios compartidos
Ocurre cuando varios host tiene acceso al mismo medio. Por ejemplo, si varios PC
se encuentran conectados al mismo cable físico, a la misma fibra óptica entonces
se dice que comparten el mismo entorno de medios.
Entorno extendido de medios compartidos
Es un tipo especial de entorno de medios compartidos en el que los dispositivos
de networking pueden ampliar el entorno de modo que pueda incluir accesos
múltiples o distancias mayores de cableado.
Redes conmutadas
Consiste en un conjunto de nodos interconectados entre si, a través de medios de
transmisión, formando la mayoría de las veces una topología mallada, donde la
información se transfiere encaminándola del nodo de origen al nodo destino
mediante conmutación entre nodos intermedios. Una transmisión de este tipo tiene
3 fases:
Establecimiento de la conexión
Transferencia de la información
Liberación de la conexión
La conmutación en un nodo a la conexión física o lógica de un camino de entrada
al nodo con un camino de salida del nodo con el fin de transferir la información que
llegue por el primer camino al segundo.la redes conmutadas son las redes de área extensa.
Las redes conmutadas se dividen en:
Conmutación de paquetes
Conmutación de circuitos
La conmutación de paquetes:
Es un método de envío de datos en una red de computadoras. Un paquete es un
grupo de información que consta de dos partes: los datos propiamente dichos y la
información de control, que indica la ruta a seguir a lo largo de la red hasta el
destino del paquete. Existe un límite superior para el tamaño de los paquetes; si
se excede, es necesario dividir el paquete en otros más pequeños.
La conmutación de circuitos:
Es un tipo de conexión que realizan los diferentes nodos de una red para lograr un
camino apropiado para conectar dos usuarios de una red de telecomunicaciones.
A diferencia de lo que ocurre en la conmutación de paquetes, en este tipo de
conmutación se establece un canal de comunicaciones dedicado entre dos
estaciones. Se reservan recursos de transmisión y de conmutación de la red para
su uso exclusivo en el circuito durante la conexión. Ésta es transparente: una vez
establecida parece como si los dispositivos estuvieran realmente conectados.
Sistemas de memoria distribuida.
Multicomputadores.
Los sistemas de memoria distribuida o multicomputadores pueden ser de dos tipos básicos. El primer de ellos consta de un único computador con múltiples CPUs comunicadas por un bus de datos mientras que en el segundo se utilizan múltiples computadores, cada uno con su propio procesador, enlazados por una red de interconexión más o menos rápida.
Sobre los sistemas de multicomputadores de memoria distribuida, se simula memorias compartidas. Se usan los mecanismos de comunicación y sincronización de sistemas multiprocesadores.
Un clúster es un tipo de arquitectura paralela distribuida que consiste de un conjunto de computadores independientes interconectados operando de forma conjunta como único recurso computacional sin embargo, cada computador puede utilizarse de forma independiente o separada.
En esta arquitectura, el computador paralelo es esencialmente una colección de procesadores secuenciales, cada uno con su propia memoria local, que pueden trabajar conjuntamente.
Cada nodo tiene rápido acceso a su propia memoria y acceso a la memoria de otros nodos mediante una red de comunicaciones, habitualmente una red de comunicaciones de alta velocidad.
Los datos son intercambiados entre los nodos como mensajes a través de la red.
Una red de ordenadores, especialmente si disponen de una interconexión de alta velocidad, puede ser vista como un multicomputador de memoria distribuida y como tal ser utilizada para resolver problemas mediante computación paralela.
Ventajas:
El número de nodos puede ir desde algunas decenas hasta varios miles (o más).
La arquitectura de paso de mensajes tiene ventajas sobre la de memoria compartida cuando el número de procesadores es grande.
El número de canales físicos entre nodos suele oscilar entre cuatro y ocho.
Esta arquitectura es directamente escalable y presenta un bajo coste para sistemas grandes.
Un problema se especifica como un conjunto de procesos que se comunican entre sí y que se hacen corresponder sobre la estructura física de procesadores.
Desventajas:
Se necesitan técnicas de sincronización para acceder a las variables compartidas.
La contención en la memoria puede reducir significativamente la velocidad.
No son fácilmente escalables a un gran número de procesadores.
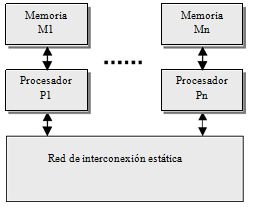
Redes de interconexión estáticas
Las redes estáticas emplean enlaces directos fijos entre los nodos. Estos enlaces, una vez fabricado el sistema son difíciles de cambiar, por lo que la escalabilidad de estas topologías es baja. Las redes estáticas pueden utilizarse con eficiencia en los sistemas en que pueden predecirse el tipo de tráfico de comunicaciones entre sus procesadores.
Clases de redes de interconexión:
Formación lineal: Se trata de una red unidimensional en que los nodos se conectan cada uno con el siguiente medianteN-1 enlaces formando una línea.
Mallas y toros: Esta red de interconexión es muy utilizada en la práctica. Las redes en toro son mallas en que sus filas y columnas tienen conexiones en anillo, esto contribuye a disminuir su diámetro. Esta pequeña modificación permite convertir a las mallas en estructuras simétricas y además reduce su diámetro a la mitad.
Propiedades más significativas:
Topología de la red: determina el patrón de interconexión entre nodos.
Diámetro de la red: distancia máxima de los caminos más cortos entre dos nodos de la red.
Latencia: retardo de tiempo en el peor caso para un mensaje transferido a través de la red.
Ancho de banda: Transferencia máxima de datos en Mbytes/segundo.
Escalabilidad: posibilidad de expansión modular de la red.
Grado de un nodo: número de enlaces o canales que inciden en el nodo.
Algoritmo de encaminamiento: determina el camino que debe seguir un mensaje desde el nodo emisor al nodo receptor.
Casos para estudio
Por numerosos motivos, el procesamiento distribuido se ha convertido en un área de gran importancia e interés dentro de la Ciencia de la Computación, produciendo profundas transformaciones en las líneas de I/D.
Interesa realizar investigación en la especificación, transformación, optimización y evaluación de algoritmos distribuidos y paralelos. Esto incluye el diseño y desarrollo de sistemas paralelos, la transformación de algoritmos secuenciales en paralelos, y las métricas de evaluación de performance sobre distintas plataformas de soporte (hardware y software). Más allá de las mejoras constantes en las arquitecturas físicas de soporte, uno de los mayores desafíos se centra en cómo aprovechar al máximo la potencia de las mismas.
Interesa realizar investigación en la especificación, transformación, optimización y evaluación de algoritmos distribuidos y paralelos. Esto incluye el diseño y desarrollo de sistemas paralelos, la transformación de algoritmos secuenciales en paralelos, y las métricas de evaluación de performance sobre distintas plataformas de soporte (hardware y software). Más allá de las mejoras constantes en las arquitecturas físicas de soporte, uno de los mayores desafíos se centra en cómo aprovechar al máximo la potencia de las mismas.
Líneas De Investigación Y Desarrollo:
Paralelización de algoritmos secuenciales. Diseño y optimización de algoritmos.
Arquitecturas multicore y multithreading en multicore.
Arquitecturas multiprocesador.
Modelos de representación y predicción de performance de algoritmos paralelos.
Mapping y scheduling de aplicaciones paralelas sobre distintas arquitecturas multiprocesador.
Métricas del paralelismo. Speedup, eficiencia, rendimiento, granularidad, superlinealidad.
Balance de carga estático y dinámico. Técnicas de balanceo de carga.
Análisis de los problemas de migración y asignación óptima de procesos y datos a procesadores. Migración dinámica.
Patrones de diseño de algoritmos paralelos.
Escalabilidad de algoritmos paralelos en arquitecturas multiprocesador distribuidas.
Implementación de soluciones sobre diferentes modelos de arquitectura homogéneas y heterogéneas (multicores, clusters, multiclusters y grid). Ajuste del modelo de software al modelo de hardware, a fin de optimizar el sistema paralelo.
Evaluación de performance.
Laboratorios remotos para el acceso transparente a recursos de cómputo paralelo.
Grandes empresas y sus implementaciones con procesamiento paralelo:
NVIDIA
PYSICS LAYER:
GPU PhysX
CPU PhysX.
Graphics Layer:
GPU –DirectX Windows
INTEL
PYSICS LAYER:
No GPU PhysX.
CPU Havok.
Graphics Layer:
GPU DirectX Windows.
AMD
PYSICS LAYER:
No GPU PhysX.
CPU Havok.
Graphics Layer:
GPU DirectX Windows.
Exposición Cmputadoras de Gama Baja, Media y Alta: